Previously, we explained our approach to uncovering hidden knowledge from response operations, much like the fabled ‘black boxes’ of aviation that reveal critical insights after an event. We continue to optimise this process, and in this blog describe how we are using cutting-edge technologies to extract, summarise, and package those insights to responders, when they need them.
Defining the problem— How do we ensure we learn our lessons?
The IFRC has a long and noble tradition of document production. Most interestingly for our purposes, national Red Cross Red Crescent (RCRC) societies document their response to emergencies - from assessment to plan of action through monitoring updates to final report. These documents allow us to find insights into what was done and why, what went well, but also not so well. All of which is consistent with the humanitarian system’s application of monitoring and evaluation as a primary way to assess its own performance, learn, and evolve (ALNAP, 2022).
However, this learning does not systematically loop back to those facing similar decisions in the future. We tend to rely upon diffusion of knowledge to improve practice, rather than engineering a means for the collection, processing and resurfacing of such insights into established workflows.

The Operational Learning Project aims to tackle this by creating a systematic learning loop from data collected from reports generated over the years by our national societies to presentation in appropriate formats across relevant IFRC platforms. It taps into the potential of global processes that have been in place for years, to produce customised real-time insights to the right people at the right time to effect operational learning.
User centred design — Learning from Learning
The Ops Learning project originated in the development of a dashboard that aimed to extract and display the learnings from DREF operations in a centralised place (more detail here). While the tool is praised for allowing easy access to learning ‘excerpts’ across many areas of interest, it is not as well used or visible as it could be. Recognising this, as well as the potential application of new technologies to help extract, summarise, and present the data in a more customisable way, a team from across Disaster Response Emergency Fund (DREF), NS Preparedness (PER), Learning, Planning, Monitoring, Evaluation and Reporting (PMER), National Society Development (NSD), and Information Management (IM) came together with the aim of making this tool even more powerful and user-centred.

As ever, we started by consulting current and potential users. The team chatted with staff in HQ, regions and countries to determine the primary needs regarding operational learning. This included defining user journeys in the generation and application of such information before, during, and after disasters. The study identified current and potential sources of data (such as DREF reports, Emergency Appeals reports, Evaluations, End of Mission reports, and debriefings) and made actionable recommendations for the operational learning dashboard. Some of the key recommendations included to a) create summaries to ease absorption of the information, b) refine the ability to filter learning excerpts by area of interest, c) introduce better data validation processes, and d) provide offline access.
Solution engineering — new ways to tackle old problems
After receiving feedback on the current and potential future state, we then started to design new solutions. This involved technical studies to explore the potential expansion of our use of Natural Language Processing* (see annex for explanation of terms). We created wireframe designs to show how solutions might look and feel, and went back to some of those initially consulted for their opinion. We found that the IFRC platforms best suited to serve users with operational learnings are GO, the Rapid Response Management System (RRMS, which supports IFRC surge deployments) and the Evaluations database, found on IFRC.org. GO is where information is consolidated during new emergencies, RRMS is used by staff when deployed to a new emergency, and the Evaluations database is used for the organisation’s reporting teams.
The new design solutions are proposed with the assumption that we are able to extract learnings from unstructured operational documents, and that we are able to generate good enough summaries of those learnings. We considered the use of Generative AI** for both of those tasks. A first step in this path was to conduct a literature review on Large Language Models to better understand the potential, limitations and risk mitigation measures to use these models. We also convened a workshop between data scientists in the IFRC, to improve the understanding of the potential of these technologies in our specific context.
Technical specifications — Applying Data Science
Here is where it might get complicated…
To extract learnings from unstructured operational documents, we aim to use a method combining a Neural Network Classifier*** and a retrieval system using Generative AI. The Neural Network Classifier comes from the fill-mask model HumBert, a model based completely on humanitarian documents, and passes through a fine-tuning step to classify a sentence between learning, challenge or other. The Generative AI part consists of using instruction learning for retrieving sentences from the suggestions given by the classifier. With a test set of DREF documents the classifier alone got an F1-score of over 0.8. The prototype code can be found here. The method needs to be further tested, validated and updated, mainly with Emergency Appeals Final Reports and Evaluation documents. Crucially, it needs to be followed by the design of a validation process with potential users.
The design solutions propose the generation of automatic summaries from filtered data (e.g., automatic generation of a summary for learnings of cyclones in Philippines in the Health sector). The introduction of tools like ChatGPT has raised the visibility of such solutions. However, as an authoritative source, we must balance the convenience and speed of such approaches with the risk of false information. Research is ongoing to propose a robust approach to produce effective summaries while addressing the potential risk of hallucination****.
Got all of that? Good, then let’s continue…
Design Sprint —Focus on leveraging Ops Learning
In September we pulled the team back together and reflected on the research insights, design solutions and potential workflows. During a three-day sprint, we weighed up different implementation options, iterated on the designs and produced a clear action plan for each aspect of the project. You can see some of our workings in the Miro board here.

Future actions— Moving from systematic to systemic learning loops
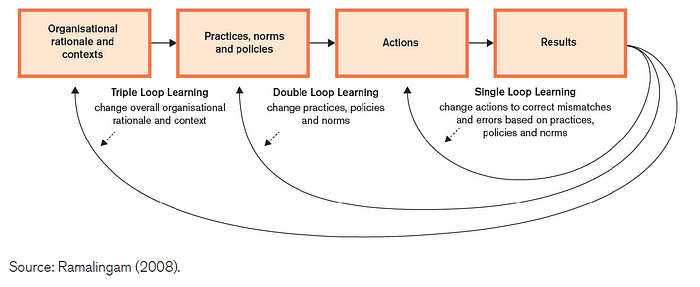
What we have agreed could be characterised as single loop learning. We are starting with the existing reports from operations supported by the IFRC (DREFs and Emergency Appeals) and using the accepted framework to gauge operational readiness. We aim to introduce the creation of summaries and integration of these on various workflows on GO, including at the initiation of operations through the DREF.
In other words, we aim to create a system to optimise and improve existing processes without questioning the underlying assumptions or norms. We feel this is an appropriate aim for an operational platform such as GO. However, we recognise the potential for this data to also lead to more fundamental questioning of our operational practice — moving from systematic to systemic learning loops (ALNAP, 2022).
Please get in touch if you have ideas on how else this dataset could be explored, exploited or expanded — im@ifrc.org
* Natural Language Processing (NLP) is a field in Artificial Intelligence and is also related to linguistics. On a high level, the goal of NLP is to programme computers to automatically understand human languages, and to automatically write/speak in human languages. We say “Natural Language” to mean human language, and to indicate that we are not talking about computer (programming) languages.
** Generative AI refers to techniques that learn a representation of artifacts from data, and use it to generate brand-new, unique artifacts that resemble but do not repeat the original data. This new paradigm shift in AI allows users to generate new content — words, images, videos — by giving prompts to the system to create specific outputs.
*** Neural Network Classifier is a machine learning model that uses artificial neural networks to categorise input data into predefined classes or categories. It consists of layers of interconnected nodes (neurons) that process and transform the input information through mathematical operations, ultimately producing a probability distribution over the possible classes, with the class having the highest probability being the predicted output. Recently, a prevalent practice involves fine-tuning pre-trained models.
**** Hallucination refers to the fabrication of information that seems factual while in fact, it is nonsensical, non-existent and can lead to grave misinformation.
